
Notice
Recent Posts
Recent Comments
Link
250x250
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- freshness
- airflow
- query history
- 모바일
- docker
- CDC
- k9s
- 쿠버네티스
- Materializations
- spark
- kafka
- KubernetesPodOperator
- mysql
- polars
- numpartitions
- 윈도우
- dbt_project
- UI for kafka
- 동적 차트
- bar cahrt
- 크롤링
- Java
- proerty
- ksql
- Python
- 카프카
- spring boot
- DBT
- 파이썬
- 도커
Archives
- Today
- Total
데이터 엔지니어 이것저것
Spark Broadcast 본문
728x90
Broadcast란?
- 전역 변수
브로드 캐스트를 사용하는 이유
클러스터의 모든 노드에서 읽기 전용 변수를 공유하여, 각 노드에서 캐시할 수 있음으로,
이를 통해 네트워크 오버헤드를 줄이고, 전반적인 성능을 향상시킬 수 있다.
일반적으로 룩업 테이블과 같은 대규모 읽기 전용 데이터 구조를 공유하는데 사용.
브로드캐스트 변수는 구성 정보 및 작업에 필요한 기타 소규모 데이터 구조를 공유하는데도 사용된다.
언제 사용하는가
- 조회 테이블 공유
여러 변환에 사용되는 대형 룩업 테이블이 있는 경우, 이 테이블을 브로드캐스트하면 각 태스크와 함께
테이블 복사본을 전송하는데 따른 오버헤드를 방지할 수 있다. - 작은 구성 개체 공유
모든 작업에서 사용해야하는 작은 구성 개체가 있는 경우 이 개체를 브로드캐스트하면
각 작업과 함께 복사본을 전송하여 오버헤드 없이 모든 작업에서 액세스 - 단계 간 데이터 공유
스파크 작업 단계 간에 데이터를 공유해야 할 때 이를 브로드캐스트 하면 네트워크 오버헤드를 줄일 수 있다.
룩업테이블이란
매핑 또는 룩업 작업을 수행하는데 사용되는 데이터 구조를 나타낸다.
키 집합과 해당 값을 저장하는 데이터 구조.
룩업 테이블의 목적은 해시 테이블이나 인덱스를 사용하여, 데이터에 대한 빡르고 효율적인 액세스를 제공
스파크에서 룩업 테이블은 조인 작업에서 한 데이터 세트의 값을 다른 데이터 세트로 매핑하는데 사용.
eg) 수백만개의 레코드가 있는 대규모 데이터 세트를 더 작은 룩업 테이블과 결합하려는 경우
룩업 테이블을 클러스터의 모든 노드에 브로드캐스트하고 메모리에 캐시한 다음 각 노드에서 로컬로 결합을 수행할 수 있다. 이는 결합 동작의 성능을 크게 향상.
또한 브로드캐스트 조회 테이블을 사용하여, 스파크에서 여러 작업에 필요한 메타데이터 또는 구성 정보를 저장할 수 있다.
- 브로드 캐스트 변수를 사용하면, 캐싱된 읽기 전용 변수를 보관하여 사용.
- 모든 워커 노드에 값을 저장하여, 재전송 없이 Spark Action 에서 사용.
- 모든 워커에 큰 규모의 데이터셋을 효율적으로 제공할 때 사용하는 방법, 읽기 전용 변수
- 여러 단계에 걸친 작업에 동일한 데이터가 필요할 때
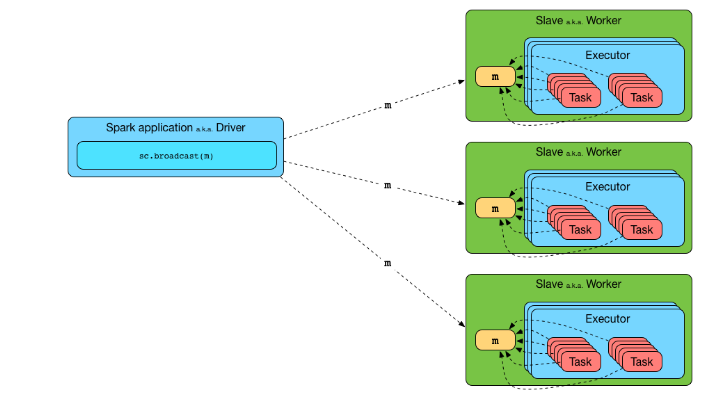
출처
https://mallikarjuna_g.gitbooks.io/spark/content/spark-broadcast.html
Broadcast variables · Spark
mallikarjuna_g.gitbooks.io
728x90
'오픈소스 > Spark' 카테고리의 다른 글
| Spark cache와 persist (0) | 2023.02.14 |
|---|---|
| Spark UDF (0) | 2023.02.05 |
| Spark Session (0) | 2023.01.08 |
| Spark SQL (0) | 2023.01.08 |
| spark groupByKey vs reduceByKey (0) | 2022.12.05 |
'오픈소스/Spark' Related Articles
more
