
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 크롤링
- 파이썬
- UI for kafka
- Materializations
- query history
- 동적 차트
- 모바일
- Java
- docker
- KubernetesPodOperator
- 카프카
- DBT
- proerty
- CDC
- spark
- mysql
- airflow
- ksql
- polars
- bar cahrt
- 윈도우
- k9s
- numpartitions
- dbt_project
- Python
- freshness
- kafka
- 도커
- 쿠버네티스
- spring boot
- Today
- Total
데이터 엔지니어 이것저것
Polars 본문
Polars
Pandas와 같은 기존의 데이터 처리 라이브러리가 가진 성능적 한계를 극복하기 위해 탄생
Rust 기반으로, 멀티스레딩과 병렬 처리를 지원, 대규모 데이터셋을 보다 빠르고 효율적으로 처리할 수 있도록 설계
요약 : Spark를 사용하기엔 데이터가 작고, Pandas로 돌리기엔 데이터가 많을때 좋다
속도
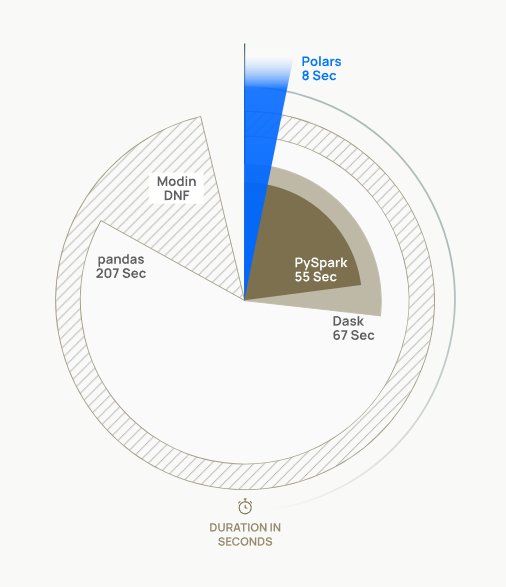
배경
기존 Pandas를 대체하기 위한 도구 탐색
평소에는 문제 없이 동작을 잘하지만, 대용량 업데이트 시, OOM이 발생.
이를 해결하기 위해 Spark를 도입하기에는 비용문제와, 기본 로직을 많이 바꿔야하는 이슈 발생
Spark를 사용해본적이 없어 도입 및 이슈 발생시 대처하는데 시간이 오래걸림.
특징
- Rust 기반으로, 외부 종속성이 없다
- I/O : 일반적인 데이터 저장 계층에 대한 최고 수준의 지원을 제공
- 직관적인 API
- Out of Core : 스트리밍 API를 사용하면, 모든 데이터가 동시에 메모리에 있을 필요 없이 결과 처리
- 병렬 : 추가 구성 없이 사용 가능한 CPU 코어에 작업 부하를 분배, 머신의 성능 최대 활용
- 벡터화된 쿼리 엔진 : Apache Arrow를 사용하여 쿼리를 벡터화된 방식으로 처리, SIMD를 사용하여 CPU 최적화
- SIMD : 병렬 컴퓨팅의 한 종류, 하나의 명령어로 여러 개의 값을 동시에 계산하는 방식
Polars와 pandas의 차이점
| 특성 | pandas | Polars |
| 언어 구현 | Python | Rust |
| 성능 | 중간, 메모리 사용 많음 | 매우 빠름, 메모리 사용 적음 |
| Lazy Evaluation | 지원하지 않음 | 지원 (LazyFrame) |
| 병렬 처리 | 지원하지 않음 | 지원 (멀티스레딩) |
| 메모리 관리 | 메모리 사용량 많음 | 메모리 효율적 |
Polars 단점
- Pandas와 호환성 부족
- 판다스에 비해 부족한 문서 및 커뮤니티
- 성능에 중점을 두어, 판다스에 비해 시각화등의 기능이 부족
추세
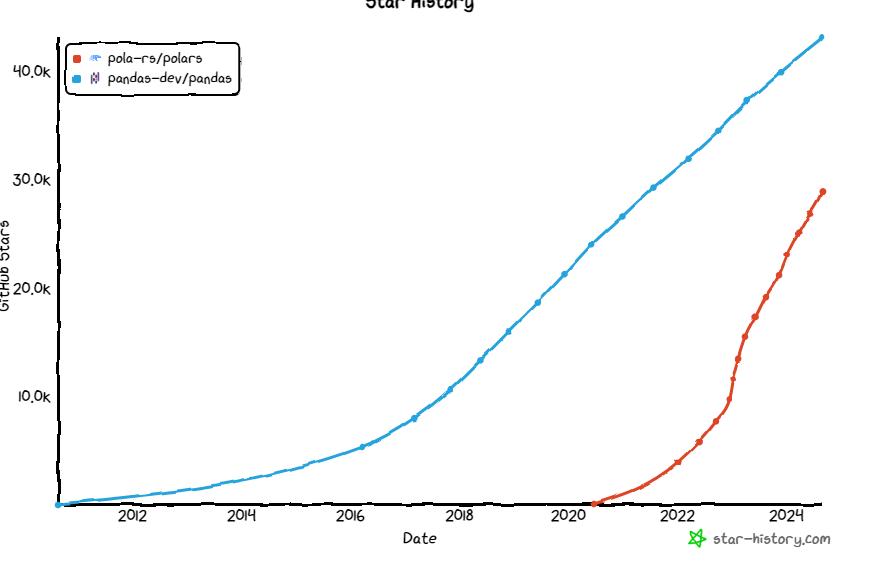
메모리 사용량 비교
import polars as pl
import pandas as pd
import numpy as np
from memory_profiler import memory_usage
# 샘플 데이터 생성
n_rows = 10**9 # 10억 행
data = {
'col1': np.random.randint(0, 100, size=n_rows),
'col2': np.random.rand(n_rows)
}
# 메모리 사용량 측정 함수
def load_with_pandas():
df = pd.DataFrame(data)
return df
def load_with_polars():
df = pl.DataFrame(data)
return df
# Pandas 메모리 사용량 측정
pandas_memory_usage = memory_usage(load_with_pandas)
print(f"Pandas Memory Usage: {max(pandas_memory_usage) - min(pandas_memory_usage)} MiB")
# Polars 메모리 사용량 측정
polars_memory_usage = memory_usage(load_with_polars)
print(f"Polars Memory Usage: {max(polars_memory_usage) - min(polars_memory_usage)} MiB")
Pandas Memory Usage: 17523.18359375 MiB
Polars Memory Usage: 0.04296875 MiB
import polars as pl
import pandas as pd
import numpy as np
import psutil
import os
# 샘플 데이터 생성
n_rows = 10**7 # 1천만 행
data = {
'col1': np.random.randint(0, 100, size=n_rows),
'col2': np.random.rand(n_rows)
}
# 메모리 사용량 측정 함수
def memory_usage_psutil():
process = psutil.Process(os.getpid())
return process.memory_info().rss / 1024**2 # 메모리 사용량(MiB)
# Pandas 메모리 사용량 측정
def load_with_pandas():
before_memory = memory_usage_psutil()
df = pd.DataFrame(data)
after_memory = memory_usage_psutil()
print(f"Pandas Memory Usage: {after_memory - before_memory} MiB")
return df
# Polars 메모리 사용량 측정
def load_with_polars():
before_memory = memory_usage_psutil()
df = pl.DataFrame(data)
after_memory = memory_usage_psutil()
print(f"Polars Memory Usage: {after_memory - before_memory} MiB")
return df
# 실행
load_with_pandas()
load_with_polars()
Pandas Memory Usage: 115.69140625 MiB
Polars Memory Usage: 0.00390625 MiB
2차 테스트
테스트 데이터 : 7473119 rows × 11 columns
pandas
start_time = time.time()
N = 10
# 'type'과 'actor_login'을 기준으로 그룹화하고, 푸시 횟수를 카운팅한 후
# 각 이벤트 타입별로 상위 N명을 출력
most_active_pushers = pandas_df.groupby(['type', 'actor_login']).size().reset_index(name='count')
# 'type'별로 상위 N명의 푸시를 가져오기
top_n_pushers = most_active_pushers.groupby('type').apply(lambda x: x.nlargest(N, 'count')).reset_index(drop=True)
end_time = time.time()
# 결과 출력
print(top_n_pushers)
print(f"실행 시간: {end_time - start_time}초")

polars
start_time = time.time()
N = 10
# 이벤트별로 그룹화하고, actor_login별로 푸시 횟수(count) 계산
most_active_pushers = (
polars_df
.group_by(["type", "actor_login"])
.agg(pl.count("id").alias("count"))
.sort("count", descending=True) # count 기준 내림차순 정렬
.head(N) # 상위 10개만 가져오기
)
end_time = time.time()
# 결과 출력
print(most_active_pushers)
print(f"실행 시간: {end_time - start_time}초")

단순 집계시, 약 3배정도의 시간차이 확인
데이터 로딩 시간까지 추가할 경우
Pandas
실행 시간: 8.623583793640137초
Polars
실행 시간: 1.56950044631958초
Lazy API를 이용시
start_time = time.time()
N = 10
polars_df= pl.scan_parquet('github.parquet')
# 이벤트별로 그룹화하고, actor_login별로 푸시 횟수(count) 계산
most_active_pushers = (
polars_df
.group_by(["type", "actor_login"])
.agg(pl.count("id").alias("count"))
.sort("count", descending=True) # count 기준 내림차순 정렬
.head(N) # 상위 10개만 가져오기
).collect()
end_time = time.time()
# 결과 출력
print(most_active_pushers)
print(f"실행 시간: {end_time - start_time}초")실행 시간: 0.9253346920013428초
참고 사이트
https://techblog.woowahan.com/18632/
Polars로 데이터 처리를 더 빠르고 가볍게 with 실무 적용기 | 우아한형제들 기술블로그
배달시간예측서비스팀은 배달의민족 앱 내의 각종 서비스(배민배달, 비마트, 배민스토어 등)에서 볼 수 있는 배달 예상 시간과 주문 후 고객에게 전달되기까지의 시간을 데이터와 AI를 활용하여
techblog.woowahan.com
Index - Polars user guide
Blazingly Fast DataFrame Library Polars is a blazingly fast DataFrame library for manipulating structured data. The core is written in Rust, and available for Python, R and NodeJS. Key features Fast: Written from scratch in Rust, designed close to the mach
docs.pola.rs
https://github.com/pola-rs/polars
GitHub - pola-rs/polars: Dataframes powered by a multithreaded, vectorized query engine, written in Rust
Dataframes powered by a multithreaded, vectorized query engine, written in Rust - pola-rs/polars
github.com
'개발언어 > Python' 카테고리의 다른 글
| 테스트 코드 - sqlite (0) | 2024.07.04 |
|---|---|
| Ray 적용하기 (0) | 2023.09.27 |
| 크롤링 ip 차단 해제 or 우회 (0) | 2021.09.26 |
| 셀레니움 자동로그인, 봇 회피 (0) | 2021.09.26 |
| Ray (0) | 2021.09.24 |