오픈소스/Spark
Spark readStream with kafka, flask
pastime
2023. 3. 15. 00:17
728x90
Flask에서 로그를 발생하여, 이를 Kafka 서버로 발송 (Producer)
스파크는 카프카에서 데이터를 가져가는 로직( Consumer)
카프카 서버 docker-compose
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.0.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
kafka:
image: confluentinc/cp-kafka:7.0.0
hostname: kafka
container_name: kafka
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_ADVERTISED_LISTENERS: "PLAINTEXT://kafka:29092,PLAINTEXT_HOST://localhost:9092"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: "PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT"
KAFKA_INTER_BROKER_LISTENER_NAME: "PLAINTEXT"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
volumes:
- ./kafka-data:/var/lib/kafka/data
flask 서버 코드
from flask import Flask
import random
import time
import logging
from confluent_kafka import Producer
# log_levels = ['INFO', 'WARNING', 'ERROR', 'DEBUG']
log_levels = [20, 30, 40, 10]
log_messages = ['Application started', 'Processing data', 'Invalid input', 'An error occurred']
conf = {
'bootstrap.servers': '127.0.0.1:9092',
'client.id': 'flask-producer'
}
logging.basicConfig(level=logging.DEBUG)
producer = Producer(conf)
app = Flask(__name__)
@app.route('/')
def generate_log():
while True:
log_level = random.choice(log_levels)
log_message = random.choice(log_messages)
current_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
msg = f"{current_time} [{log_level}] {log_message}"
print(msg)
producer.produce('logs', msg.encode('utf-8'))
producer.flush()
time.sleep(0.1)
# return f'{current_time} [{log_level}] {log_message}'
if __name__ == '__main__':
app.run(port=5000, debug=True)
import org.apache.log4j._
import org.apache.spark.sql.SparkSession
import org.apache.spark._
import org.apache.spark.sql.functions._
object spark_streaming_test {
def main(args: Array[String]) {
// Set the log level to only print errors
Logger.getLogger("org").setLevel(Level.ERROR)
// Create SparkSession
val spark = SparkSession.builder()
.appName("StreamReaderExample")
.master("local[*]")
.getOrCreate()
val bootstrapServers = "127.0.0.1:9092"
val topic = "logs"
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", bootstrapServers)
.option("subscribe", topic)
.option("startingOffsets", "latest")
.load()
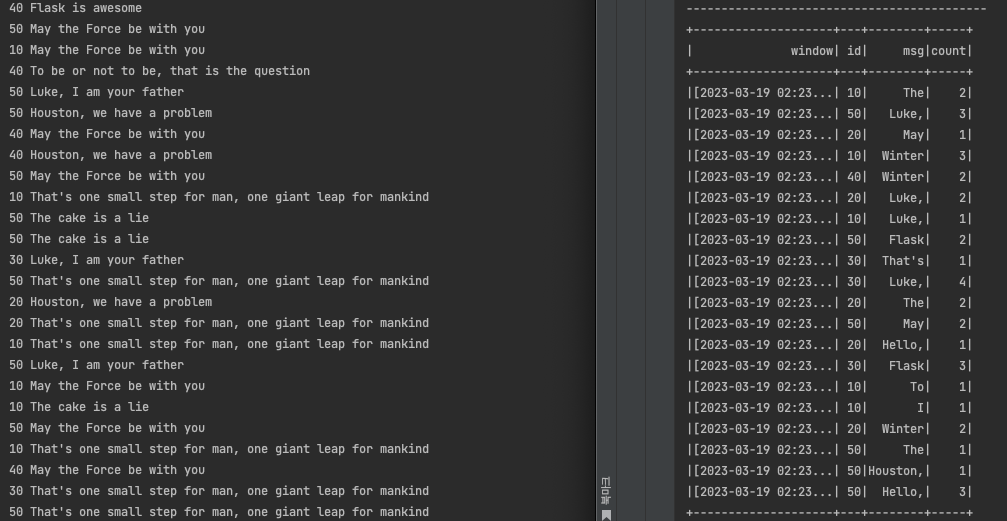
val query = df
.withWatermark("timestamp", "1 seconds") // watermark 적용
.select(
split(col("value"), " ").getItem(0).as("id"),
split(col("value"), " ").getItem(1).as("msg")
, col("timestamp")
)
.groupBy(window(col("timestamp"), "1 second"), col("id"), col("msg"))
.count()
.writeStream
.outputMode("append")
.format("console")
.start()
query.awaitTermination()
}
}

728x90