
Notice
Recent Posts
Recent Comments
Link
250x250
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- Python
- k9s
- 모바일
- CDC
- KubernetesPodOperator
- mysql
- polars
- query history
- 카프카
- ksql
- spark
- numpartitions
- DBT
- bar cahrt
- Materializations
- UI for kafka
- airflow
- dbt_project
- kafka
- 쿠버네티스
- 크롤링
- 동적 차트
- 파이썬
- 윈도우
- freshness
- spring boot
- Java
- 도커
- docker
- proerty
Archives
- Today
- Total
데이터 엔지니어 이것저것
서울시 인구-CCTV 현황 산점도 본문
728x90
# 라이브러리 임포트
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import platform
from matplotlib import font_manager, rc # 글꼴 처리 준비
# 주피터 노트북에서 시각화 결과가 직접 출력되도록 설정
%matplotlib inline
# 판다스 데이터프레임 실수 출력 형식 지정
pd.options.display.float_format = '{:,.1f}'.format # 운영체제에 적합한 한글 글꼴 지정
plt.rcParams['axes.unicode_minus'] = False # '-' 부호가 정상적으로 출력되도록 설정
if platform.system() == 'Darwin': # 운영체제가 MAC OS X라면
rc('font', family='AppleGothic') # 애플고딕 글꼴 지정
elif platform.system() == 'Windows': # 운영체제가 윈도우라면
path = "c:/Windows/Fonts/malgun.ttf" # 글꼴 파일 경로 지정
font_name = font_manager.FontProperties(fname=path).get_name() # 글꼴 이름 획득
rc('font', family=font_name) # 획득한 글꼴 이름으로 지정
else: # 기타 운영체제라면
print('Unknown system... sorry~~~~') # 글꼴 설정 실패 메시지 출력# 연도를 지정하여 인구 데이터를 입력하는 함수 실행
df_pop2015 = read_pop('2015') # 1) 2015 인구 획득
df_pop2020 = read_pop('2020') # 2) 2020 인구 획득
# 인구 데이터 병합
df_pop = pd.merge(
df_pop2015,df_pop2020,
how='outer',
on='자치구'
)
df_pop.head()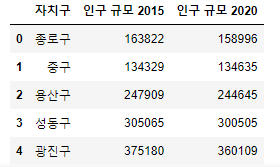
# CCTV 데이터 파일 읽어오기
df_cctv = pd.read_csv(
'CCTV.csv',# 파일 경로 지정
thousands = ',',# 천 단위 구분 쉼표 처리
header = 1,# (0부터 시작하는 번호 기준으로) 1번 행을 헤더로 지정
encoding='cp949' # 인코딩 방식 지정
)
# 열 이름 변경
df_cctv.rename(
columns={
'구분': '자치구',
'2011년 이전' : '2010년 이전'
}, # '구분'을 '자치구'로, '2011년 이전'을 '2010년 이전'으로 변경
inplace=True # 원본을 직접 수정
)
lst_col = ['2010년 이전', '2011년', '2012년', '2013년', '2014년', '2015년']
df_cctv['CCTV 규모 2015'] = df_cctv[lst_col].sum(axis=1)
df_cctv
# 2015년 합계 계산
lst_col = ['2010년 이전', '2011년', '2012년', '2013년', '2014년', '2015년']
df_cctv['CCTV 규모 2015'] = df_cctv[lst_col].sum(axis=1)
# 2020년 합계 계산
lst_col = ['2010년 이전', '2011년', '2012년', '2013년', '2014년', '2015년', '2016년', '2017년', '2018년', '2019년', '2020년']
df_cctv['CCTV 규모 2020'] = df_cctv[lst_col].sum(axis=1)

rows = df_cctv.index[0]
df_cctv.drop(rows, inplace=True) # 합계 행을 삭제
# 불필요한 열 삭제 ('자치구', 'CCTV 규모 2015', 'CCTV 규모 2020' 열만 남기고 다른 열은 제거)
cols = ['총계', '2010년 이전', '2011년', '2012년', '2013년', '2014년', '2015년', '2016년', '2017년', '2018년', '2019년', '2020년']
df_cctv.drop(cols, axis=1, inplace=True)
# '자치구' 열 내부의 공백 제거 (예를 들어 '중 구'를 '중구'로 수정)
df_cctv['자치구'] = df_cctv['자치구'].str.replace(' ','')
# 결과 출력
df_cctv.head()
# 인구와 CCTV 병합
cctv_with_pop = pd.merge( # 병합 함수 호출
df_pop,df_cctv, # 병합 대상은 인구 및 CCTV
how='outer',# 외부 조인 방식
on='자치구'# 조인 기준 열 지정
)
# 자치구를 인덱스로 설정
cctv_with_pop.set_index('자치구' , inplace=True)
# 병합 결과 출력
cctv_with_pop.head()
# 인구 백명당 CCTV 비율 계산
cctv_with_pop['CCTV 비율 2015'] = cctv_with_pop['CCTV 규모 2015'] / cctv_with_pop['인구 규모 2015'] * 100
cctv_with_pop['CCTV 비율 2020'] = cctv_with_pop['CCTV 규모 2020'] / cctv_with_pop['인구 규모 2020'] * 100
# 계산 결과 출력
cctv_with_pop.head()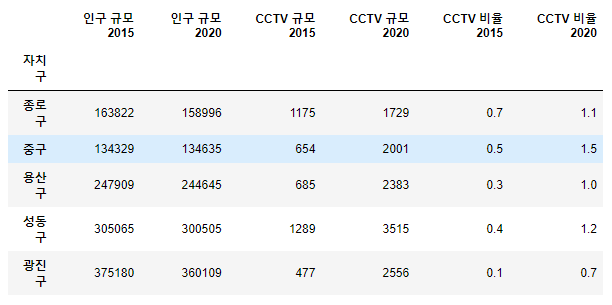
# 회귀선 준비
pf2015 = np.polyfit( # numpy.polyfit(x, y, 차수)
cctv_with_pop['인구 규모 2015'], # 추정에 사용할 x 좌표 값
cctv_with_pop['CCTV 규모 2015'], # 추정에 사용할 y 좌표 값
1 # 1차원(직선 형태) 다항식
)
pf2020 = np.polyfit( # numpy.polyfit(x, y, 차수)
cctv_with_pop['인구 규모 2020'], # 추정에 사용할 x 좌표 값
cctv_with_pop['CCTV 규모 2020'], # 추정에 사용할 y 좌표 값
1 # 1차원(직선 형태) 다항식
)
# y 축
fy2015 = np.poly1d(pf2015) # 2015년 회귀선 y 값 리스트 계산
fy2020 = np.poly1d(pf2020) # 2020년 회귀선 y 값 리스트 계산
# x 축
fx2015 = np.linspace(100000, 700000, 100000) # 2015년 회귀선 x 값 리스트 계산
fx2020 = np.linspace(100000, 700000, 100000) # 2015년 회귀선 x 값 리스트 계산
# 오차
cctv_with_pop['오차 2015'] = np.abs( # 2015년 오차 계산
cctv_with_pop['CCTV 규모 2015'] - fy2015(cctv_with_pop['인구 규모 2015'])
)
cctv_with_pop['오차 2020'] = np.abs( # 2020년 오차 계산
cctv_with_pop['CCTV 규모 2020'] - fy2020(cctv_with_pop['인구 규모 2020'])
)
# 결과 출력
cctv_with_pop.head()
# 자치구마다 이동 거리 계산
cctv_with_pop['이동 거리'] = np.sqrt(
((1.0 * (cctv_with_pop['인구 규모 2020'] - cctv_with_pop['인구 규모 2015']))**2) # 1배로 스케일링
+ (100*(cctv_with_pop['CCTV 규모 2020'] - cctv_with_pop['CCTV 규모 2015']))**2 # 100배로 스케일링
)
# 최대 이동 거리 확인
max_distance = cctv_with_pop['이동 거리'].max()
# 결과 출력
cctv_with_pop.head()
# 산점도 준비 및 y축 범위 설정
plt.figure(figsize=(14, 10)) # 그림 크기 (14, 10)으로 설정
plt.ylim(0,7000) # y 축 범위 (0, 7000)으로 설정
# 산점도 시각화 함수 정의
def myScatter(year, alpha, fx, fy):
# 1) 산점도 그리기
plt.scatter( # 산점도 출력 함수
x=cctv_with_pop[f'인구 규모 20{year}'], # x
y=cctv_with_pop[f'CCTV 규모 20{year}'], # y
c=cctv_with_pop[f'오차 20{year}'], # 마커 색상 (오차 데이터를 마커 색상으로 지정)
s=cctv_with_pop[f'CCTV 비율 20{year}'] *1000, # 마커 크기 (해당 연도 CCTV 비율의 제곱근에 비례)
alpha=alpha # 투명도
)
# 2) 추세선 그리기
p = np.poly1d(np.polyfit(fx, fy,1))
plt.plot(fx, p(fx), ls='-', lw=3, color='g', alpha=alpha) # 추세선 출력 함수(실선, 두께 3, 색상 초록, 투명도 알파)
# 3) 마커 레이블 출력
for n in range(len(cctv_with_pop)): # df 행 개수만큼 반복
plt.text( # 자치구 레이블 출력 함수
fx[n], # 텍스트 위치 x (자치구 원 중심의 x 좌표 값)
fy[n], # 텍스트 위치 y (자치구 원 중심의 y 좌표 값)
f"{cctv_with_pop.index[n]}{str(year)}" , # 텍스트 내용 (예: '강남구20' 또는 '강남구15')
fontsize=12 # 폰트 크기
)
# # 산점도 시각화 함수 실행
myScatter('15', 0.2, cctv_with_pop[f'인구 규모 2015'], cctv_with_pop[f'CCTV 규모 2015']) # 2015년 산점도 시각화 함수 실행, 투명도는 0.2로 지정
myScatter('20', 0.9, cctv_with_pop[f'인구 규모 2020'], cctv_with_pop[f'CCTV 규모 2020']) # 2020년 산점도 시각화 함수 실행, 투명도는 0.9로 지정
# 자치구 이동 궤적 출력
for i in range(len(cctv_with_pop)): # df 행 개수만큼 반복
distance = cctv_with_pop['이동 거리'][i] # n번 자치구 이동 거리
x_values = [ # n번 자치구의 x 좌표 리스트 시작
cctv_with_pop['인구 규모 2015'][i], # 2015년 x 좌표
cctv_with_pop['인구 규모 2020'][i] # 2020년 x 좌표
] # n번 자치구의 x 좌표 리스트 종료
y_values = [ # n번 자치구의 y 좌표 리스트 시작
cctv_with_pop['CCTV 규모 2015'][i], # 2015년 y 좌표
cctv_with_pop['CCTV 규모 2020'][i] # 2020년 y 좌표
] # n번 자치구의 y 좌표 리스트 종료
plt.plot( # 2015년 위치에서 2020년 위치로 이동 궤적 출력 함수
x_values, # n번 자치구의 x 좌표 리스트
y_values, # n번 자치구의 y 좌표 리스트
lw=(distance/max_distance)*10, # 이동 궤적 두께를 최대 이동거리 대비 해당 자치구 이동거리 비율의 10배로 지정
color='b',alpha=0.3 # 이동 궤적 색상의 blue 값을 최대 이동거리 대비 해당 자치구 이동거리 비율로, 투명도를 0.3으로 지정
)
# 마무리
plt.colorbar() # 색상 조견 막대 출력 함수 (수직 방향)
plt.title('2015-2020 인구 및 CCTV 규모 산점도') # 산점도 제목 지정
plt.xlabel('인구 규모 (단위: 명)') # x축 제목 지정
plt.ylabel('CCTV 설치 규모 (단위: 대)') # y축 제목 지정
plt.grid() # 눈금 그리드 보이도록 지정
plt.show() # 시각화 결과 출력
728x90
'기타 > 데이터 분석 및 시각화' 카테고리의 다른 글
| Lux (0) | 2021.11.18 |
|---|---|
| 타이타닉 분석 (0) | 2021.09.11 |
| 판다스 프로파일링 (0) | 2021.09.09 |
| 워드 클라우드 (0) | 2021.06.03 |
| 비트코인 데이터 분석 (0) | 2021.03.28 |
'기타/데이터 분석 및 시각화' Related Articles
more

